Web Scraper API
Fetch real-time data from 100+ websites,No development or maintenance required.
SCRAPING SOLUTIONS
Get accurate and in real-time results sourced from Google, Bing, and more.
With 120+ prebuilt and custom scrapers ready for any use case.
No blocks, no CAPTCHAs—unlock websites seamlessly at scale.
Execute scripts in stealth browsers with full rendering and automation
PROXY INFRASTRUCTURE
Over 100 million real residential IPs from genuine users across 190+ countries.
Reliable mobile data extraction, powered by real 4G/5G mobile IPs.
For time-sensitive tasks, utilize residential IPs with unlimited bandwidth.
Fast and cost-efficient IPs optimized for large-scale scraping.
SCRAPING SOLUTIONS
PROXY INFRASTRUCTURE
DATA FEEDS
Full details on all features, parameters, and integrations, with code samples in every major language.
LEARNING HUB
ALL LOCATIONS Proxy Locations
TOOLS
RESELLER
Get up to 50%
Contact sales:partner@thordata.com
Products $/GB
Fetch real-time data from 100+ websites,No development or maintenance required.
Get real-time results from search engines. Only pay for successful responses.
Execute scripts in stealth browsers with full rendering and automation.
Bid farewell to CAPTCHAs and anti-scraping, scrape public sites effortlessly.
Dataset Marketplace Pre-collected data from 100+ domains.
Over 100 million real residential IPs from genuine users across 190+ countries.
Reliable mobile data extraction, powered by real 4G/5G mobile IPs.
For time-sensitive tasks, utilize residential IPs with unlimited bandwidth.
Fast and cost-efficient IPs optimized for large-scale scraping.
Data for AI $/GB
Pricing $0/GB
Docs $/GB
Full details on all features, parameters, and integrations, with code samples in every major language.
Resource $/GB
EN $/GB
产品 $/GB
AI数据 $/GB
定价 $0/GB
产品文档 $/GB
资源 $/GB
简体中文 $/GB
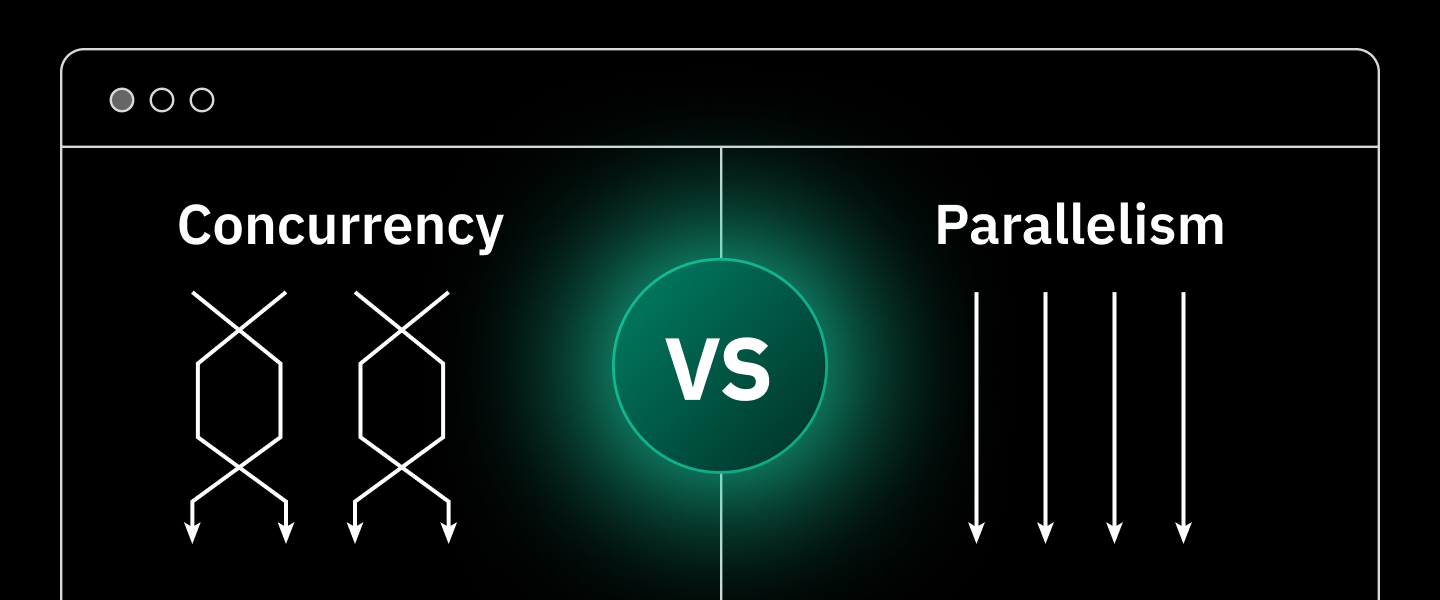

Concurrency involves managing multiple tasks by interleaving their execution, creating an illusion of simultaneity, while parallelism entails true simultaneous execution across multiple processing units. This article explains each concept, describes common models and real-world use cases, compares their trade-offs, and offers guidance on when to favor one approach over the other—while showing how they can be combined effectively.
At its core, concurrency refers to the ability of a system to manage multiple tasks that are in progress during overlapping periods of time — even if they’re not literally running at the same instant.
Imagine a single cashier at a store handling multiple customers: the cashier may serve customer A for a while, then pause to help customer B when A is waiting for change, then return to A, and so on. The tasks (serving customers) overlap in time, but only one is being actively served at any given moment. That is concurrency.
In computing, concurrency is often realized via threads, coroutines, asynchronous I/O, or event loops. For instance, a single-core processor can switch between multiple threads — or tasks — so quickly that to a user, it seems as if tasks are happening simultaneously, even though under the hood there is only one task executing at any moment.
Because tasks are interleaved, concurrency greatly improves responsiveness and resource utilization — especially in environments with I/O-bound operations (like network requests, file reads/writes, or user interactions). When one task is blocked waiting for I/O, the system can switch to another, avoiding idle CPU time.
Thus, concurrency is less about doing many things simultaneously, and more about effectively managing many tasks so that a system remains responsive and efficient.
In contrast, parallelism refers to the actual simultaneous execution of multiple tasks — or subtasks — at the same time, using multiple processing units (such as CPU cores, multiple CPUs, GPU cores, or distributed systems).
Returning to the cashier analogy: parallelism would be like having multiple cashiers serving different customers at the same moment. Each cashier works independently — truly in parallel — leading to faster throughput because several tasks proceed concurrently without waiting on each other.
Parallelism is about execution: splitting a problem into subtasks that run simultaneously on separate cores, processors, or machines to reduce wall-clock time for CPU-intensive workloads. Where concurrency is a design strategy for interleaving work, parallelism is literal simultaneous computation.
Parallelism demands hardware support: a multi-core CPU (or multiple processors) or a distributed computing environment. Without that, tasks cannot execute truly simultaneously. A multi-core setup allows for real concurrency at the hardware level, turning the illusion of concurrency into real parallel execution.
Implementations of concurrency vary by programming model. Some common models are:
Cooperative multitasking: Tasks voluntarily yield control at safe points. It’s simple but requires well-behaved code (examples include coroutine-based designs).
Preemptive multitasking: The scheduler forcibly interrupts tasks to ensure fairness, typical of operating systems and traditional threading.
Event-driven concurrency: A single loop dispatches small non-blocking tasks (I/O callbacks, promises). This is the core model behind Node.js and many async frameworks.
Actor model: Independent “actors” exchange messages asynchronously; each actor processes one message at a time, minimizing shared state and locking. This model underpins Erlang and Akka.
Reactive programming: Systems model streams of events and react to changes, often used to structure complex, asynchronous data flows.
Each model has trade-offs in complexity, suitability for I/O vs CPU work, and ease of reasoning about correctness. For example, event loops simplify single-threaded concurrency but place the burden on non-blocking APIs; actor systems reduce shared-state bugs but require thinking in messages.
Parallelism also comes in several flavors:
Data parallelism: The same operation runs across subsets of data in parallel (e.g., map operations on large arrays, SIMD). It is common in numeric computing and machine learning.
Task parallelism: Independent tasks execute concurrently on different processors (e.g., thread pools processing distinct requests).
Pipeline parallelism: Work flows through stages that can operate concurrently (useful in streaming and media processing).
Fork/Join and divide-and-conquer: A large task is recursively split into subtasks, executed in parallel, and then combined (common in parallel sorting and many algorithms). ([Bright Data][2])
GPU/accelerator parallelism: Thousands of lightweight threads run on GPUs for highly parallel workloads (deep learning, image processing). Libraries like CUDA and OpenCL enable this.
Selecting a parallelism model is driven by the problem’s structure: whether it can be decomposed into independent pieces, how much communication and synchronization are required, and the available hardware.
Web server handling requests
A single-machine web server uses concurrency to handle many I/O-bound HTTP requests without blocking. The server interleaves request handlers so one slow database query doesn’t stall all other requests. If the server also has CPU-heavy tasks (e.g., image thumbnail generation), it can offload those into parallel workers or a process pool so CPU work runs in parallel on multiple cores. This is a classic concurrency-for-I/O, parallelism-for-CPU split.
Bulk web scraping
Downloading hundreds of pages benefits from concurrency—many simultaneous non-blocking network requests—while parsing and analyzing scraped content benefits from parallelism across CPU cores. Oxylabs’ example shows how switching from a sequential downloader to a thread pool reduced run time from minutes to seconds.
Scientific simulation
Large numerical simulations often require parallelism (MPI, OpenMP, GPU kernels), because the workload naturally decomposes and performance depends on true simultaneous execution across processors. Concurrency plays a lesser role here unless the simulation also needs to coordinate many I/O events or user interactions.
The following code snippet demonstrates how to implement concurrency and parallelism in the same application using Python:
import asyncio, os, re
from concurrent.futures import ProcessPoolExecutor
from thordata.async_client import AsyncThordataClient
def analyze(html: str) -> int:
"""Simple CPU-bound work: count words in the HTML."""
return len(re.findall(r"\w+", html))
async def fetch_and_analyze(client, url, pool):
# 1) async I/O: scrape page via Thordata
html = await client.universal_scrape(url=url, js_render=False, output_format="HTML")
if isinstance(html, bytes):
html = html.decode("utf-8", "ignore")
# 2) CPU-bound: run in a separate process
loop = asyncio.get_running_loop()
word_count = await loop.run_in_executor(pool, analyze, html)
print(f"{url} -> {word_count} words")
async def main():
urls = ["https://www.thordata.com", "https://openai.com", "https://www.python.org"]
async with AsyncThordataClient(
scraper_token=os.environ["THORDATA_SCRAPER_TOKEN"],
public_token=os.getenv("THORDATA_PUBLIC_TOKEN", ""),
public_key=os.getenv("THORDATA_PUBLIC_KEY", ""),
) as client, ProcessPoolExecutor(max_workers=4) as pool:
await asyncio.gather(*(fetch_and_analyze(client, u, pool) for u in urls))
if __name__ == "__main__":
asyncio.run(main())Resource usage: Concurrency is typically implemented on single cores via context switching (though can also map to many cores); parallelism requires multiple cores/processors.
Goal: Concurrency aims to improve responsiveness and utilization; parallelism aims to reduce execution time by doing more work simultaneously.
Synchronization: Concurrency often needs careful coordination to avoid blocking points (locks, event loops), while parallelism emphasizes partitioning and minimizing inter-thread communication to scale.
Overhead: Concurrency can incur frequent context switching overhead; parallelism minimizes that by distributing tasks to separate cores but pays cost in inter-process communication and synchronization.
Many real systems benefit from both approaches. A sensible pattern is:
1. Identify I/O-bound vs CPU-bound parts of the workflow. I/O operations (network, disk) are usually best handled concurrently (non-blocking or many threads), while CPU-heavy operations are best parallelized across cores.
2. Use an event loop or async runtime to manage many short-lived I/O tasks without occupying CPU cores unnecessarily.
3. Offload CPU work to worker pools or process pools so parallel execution takes advantage of multiple cores and avoids the Global Interpreter Lock (GIL) limitations in some environments. Languages and runtimes offer patterns and libraries for this (thread pools, ProcessPoolExecutor, task queues).
4. Synchronize consciously: when combining models, use well-understood synchronization primitives (queues, futures, message passing) and minimize shared mutable state to reduce race conditions.
The combination is commonly called parallel concurrent execution: software can interleave many I/O tasks while simultaneously executing CPU subtasks in parallel on separate cores. This hybrid approach often yields the best latency and throughput for full-stack systems.
If the primary challenge is latency and responsiveness (many clients, network I/O), prioritize concurrency. Use asynchronous frameworks, event loops, or threads that handle I/O efficiently.
If the primary challenge is heavy computation and throughput (numerical computations, large-scale data processing), prioritize parallelism and scale across cores, nodes, or GPUs.
If both constraints are present, adopt a hybrid architecture: concurrent I/O front-end + parallel processing back-end (e.g., async server that dispatches CPU jobs into a process pool).
• Example: an engineering checklist for a hybrid system
• Profile: measure where wall-clock time is spent (I/O waits vs CPU).
• Design modules: keep I/O and CPU modules loosely coupled with clear interfaces (message queues, RPC).
• Implement concurrency: use async frameworks or controlled thread pools for network/disk I/O.
• Implement parallelism: use process pools, distributed workers, or GPUs for CPU tasks.
• Test under load: simulate real traffic patterns and large datasets to identify contention and bottlenecks.
• Monitor and tune: adjust thread counts, pool sizes, and task granularity based on observed metrics.
While both aim to improve performance, concurrency and parallelism differ fundamentally in approach, execution, and application.
|
Aspect |
Concurrency |
Parallelism |
|
Focus |
Managing multiple tasks |
Executing multiple tasks |
|
Execution |
Interleaved on single core |
Simultaneous on multiple cores |
|
Resource Needs |
Single processor sufficient |
Requires multi-core/processor setup |
|
Context Switching |
Frequent |
Minimal |
|
Use Cases |
I/O-bound (e.g., networking) |
CPU-bound (e.g., computations) |
|
Complexity |
Handles dependencies via switching |
Requires task independence |
|
Performance Goal |
Responsiveness and efficiency |
Speed and throughput |
In web scraping, concurrency accelerates by handling multiple HTTP requests non-blockingly, reducing wait times for server responses. Tools like Python’s concurrent. futures enable threading for fetching pages from sites like Wikipedia, slashing times from minutes to seconds.
Parallelism complements by processing scraped data—parsing HTML or analyzing content—across cores. Combining them, as in using proxies to distribute requests and avoid bans, enhances scalability. Services like web scraper APIs integrate these for robust data extraction, supporting large-scale operations in e-commerce monitoring or market research.
Proxies (residential or datacenter) further aid by rotating IPs, ensuring concurrency doesn’t trigger blocks. This synergy is vital for data-intensive fields, where efficiency translates to competitive advantages.
Thordata’s tools, such as the Web Scraper API and Scraping Browser, are designed to fully leverage these technologies. They enable asynchronous, parallel data collection from multiple sources, facilitating rapid data analysis and organization. Therefore, choosing a data provider like Thordata, which has integrated concurrency and parallelism into its core services, can save you time and effort.
Concurrency and parallelism are complementary tools in a systems designer’s toolbox. Concurrency structures programs to remain responsive while managing many overlapping tasks; parallelism speeds up compute-heavy work by distributing it across hardware. Knowing the difference—and when to apply each—enables architects and developers to build systems that are both fast and reliable. In practice, the most effective systems combine concurrency for I/O responsiveness with parallelism for computational throughput, while avoiding common pitfalls through profiling, sound synchronization practices, and careful tuning.
Frequently asked questions
When to use concurrency instead of parallelism?
Use concurrency when your web crawler is mostly I/O-bound—such as handling many network requests—because overlapping tasks improves efficiency without needing multiple CPU cores./p>
What is the difference between concurrency and parallelism?
Concurrency manages multiple tasks that make progress in overlapping time, while parallelism runs multiple tasks at the exact same time on different CPU cores.
About the author
Yulia is a dynamic content manager with extensive experience in social media, project management, and SEO content marketing. She is passionate about exploring new trends in technology and cybersecurity, especially in data privacy and encryption. In her free time, she enjoys relaxing with yoga and trying new dishes.
The thordata Blog offers all its content in its original form and solely for informational intent. We do not offer any guarantees regarding the information found on the thordata Blog or any external sites that it may direct you to. It is essential that you seek legal counsel and thoroughly examine the specific terms of service of any website before engaging in any scraping endeavors, or obtain a scraping permit if required.
 Looking for
Top-Tier Residential Proxies?您在寻找顶级高质量的住宅代理吗?
Looking for
Top-Tier Residential Proxies?您在寻找顶级高质量的住宅代理吗?
How to Scraping Dynamic Websites with Python?
In this article, learn how to ...
Anna Stankevičiūtė
2026-03-03

Scraping Yahoo Finance using Python
Xyla Huxley Last updated on 2026-03-02 10 min read […]
Unknown
2026-03-03

TCP Deep Dive with Wireshark
Xyla Huxley Last updated on 2026-03-03 6 min read TCP i […]
Unknown
2026-03-03

Web Scraping with Python using Requests
Xyla Huxley Last updated on 2026-03-03 6 min read Web c […]
Unknown
2026-03-03

Crawl4AI: Open-Source AI Web Crawler with MCP Automation
Xyla Huxley Last updated on 2026-03-03 10 min read AI a […]
Unknown
2026-03-03

Using Wget with Python: A Practical Guide for Reliable, Scalable Web Data Retrieval
Xyla Huxley Last updated on 2026-03-03 10 min read […]
Unknown
2026-03-03

How to Make HTTP Requests in Node.js With Fetch API (2026)
A practical 2026 guide to usin ...
Kael Odin
2026-03-03

How to Scrape Job Postings in 2026: Complete Guide
A 2026 end-to-end guide to scr ...
Kale Odin
2026-03-03

BeautifulSoup Tutorial 2026: Parse HTML Data With Python
A 2026 step-by-step BeautifulS ...
Kael Odin
2026-03-03
